Changelog
Next generation dbt UX
Viewing a dbt model file now shows you pertinent details about that model, split into three tabs: Overview, Compiled SQL, and Preview:
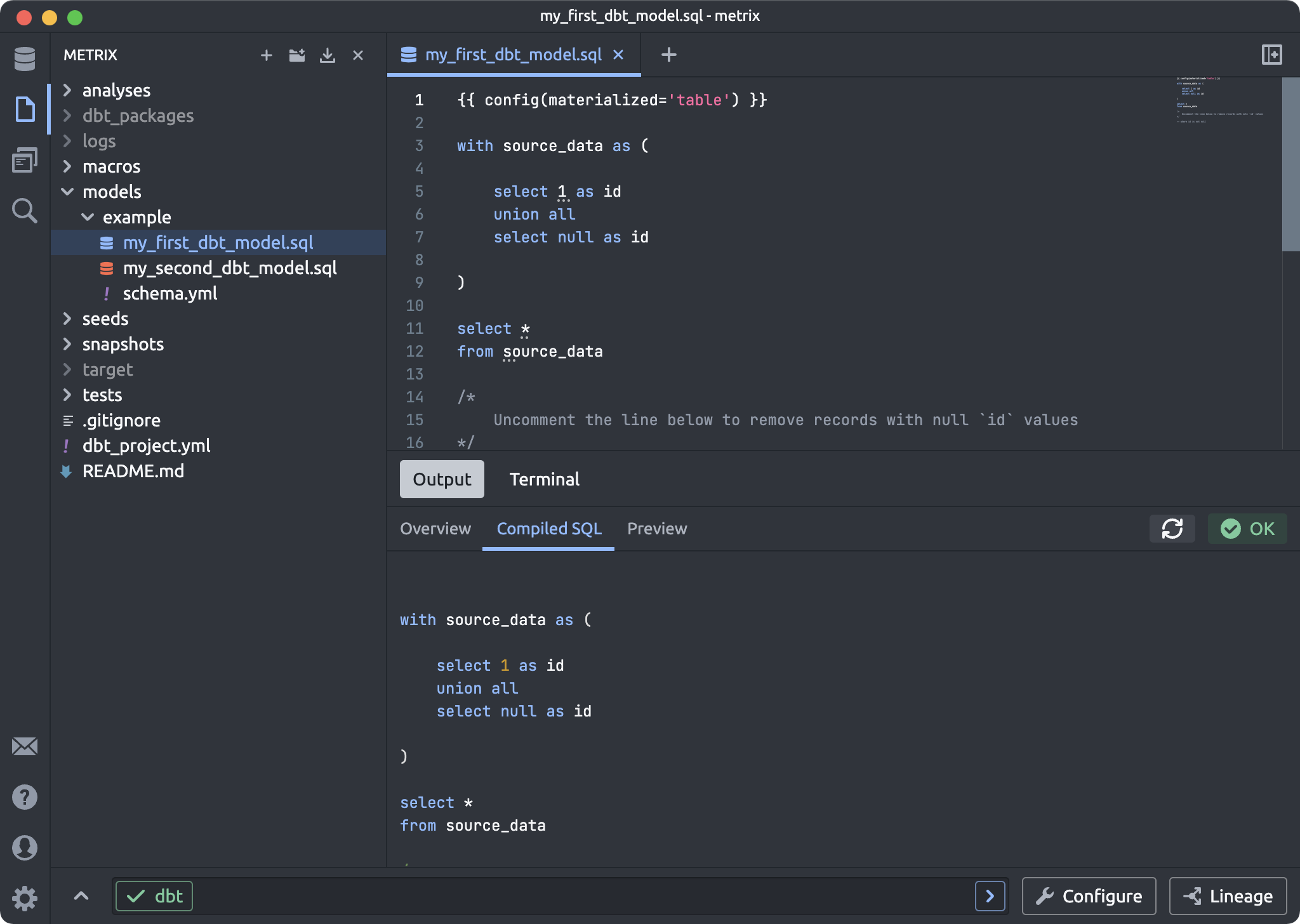
The Overview tab shows general information about the model and can perform basic actions like run and test. In future versions, we will be adding more information about the model here, including the model's schema, parents/children models, and documentation from YML files.
The Compiled SQL tab shows you the compiled SQL of the model, and is refreshed upon each file save.
The Preview tab shows a preview of the results for your model. You can refresh the preview manually, or you can turn on "Automatic preview refresh" in the Settings to have the preview automatically refreshed on each file save.
dbt command bar
The dbt command bar is now visible at all times and slides open to reveal your history of dbt commands and logs.
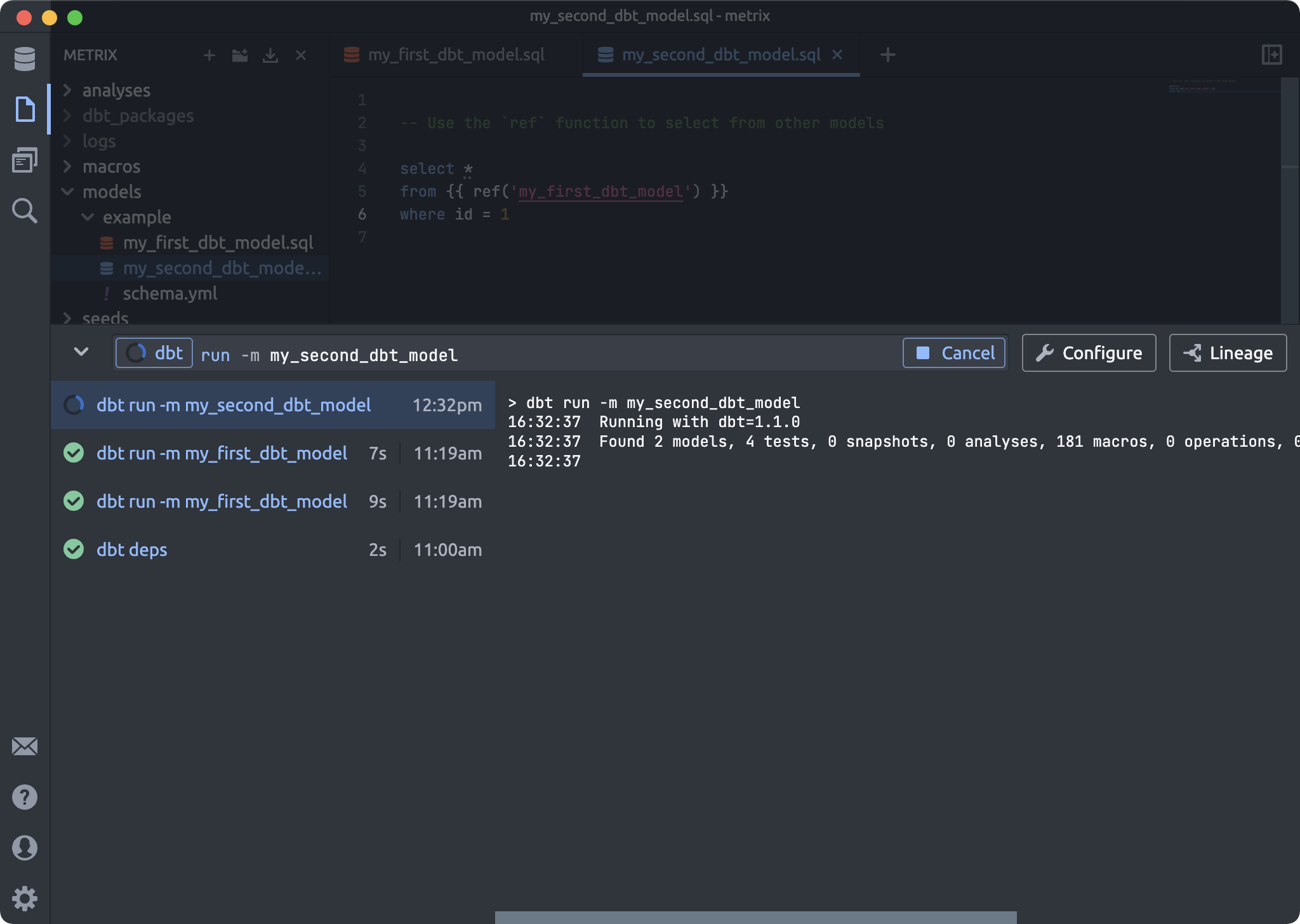
dbt command completion
Remembering and writing dbt commands can be tricky and time consuming. The new dbt command bar implements autocomplete suggestions for the most popular commands and their options:

With dbt command completion, we suggest options in commands in the same way as we do when you edit a model, and every suggestion comes with a description and documentation link. We current suggestion completions for:
- All commands (e.g.
run) - All global options (e.g.
--debug) - All subcommands (e.g.
docs generate) - All options for commands (e.g.
--fail-fast) - All values for options that have specific possible values (e.g.
--output json) - Completion of models for model selectors (e.g.
-s my_model)
In future releases, we will add support for suggestions of project file paths, tags, sources, and more!
YML file validation
Linting Improvements
Wildcard/compound passing
Now a query that looks like this:
select x_count from (
select * from (
select 1 as {{ x }}_count
) t
) t
will not display errors, because the column _count exists, but this query:
select x_wrong from (
select * from (
select 1 as {{ x }}_count
) t
) s
Would display an error:
Unable to resolve column "x_wrong"
Wildcard column for not synced connections
To build our powerful linting engine, we're fetching a relational schema for a provided connection — we call this "syncing". However, things do not always go to plan and some connections, either just created or after experiencing a network error, could end up without up-to-date synced data.
Previously, if we would end up without data about columns like that, we highlighted any columns in queries that relied on it as errors, which was a false negative — we didn't know anything about these columns, after all. Now, we treat connections that have not yet been synced as a wildcard, and start highlighting missing columns only after we successfully sync a connection, but still lint other errors while we're syncing.
Support lateral flatten alias
We added better support for the flatten Snowflake function, treating it's output as a wildcard, and fixed a number of issues related to it.
This query:
select 1
from (select 3 x) t,
lateral flatten(input => parse_json('{"a":1, "b":[77,88], "c": {"d":"X"}}')) as r,
lateral (select 1, 2) s where t.x > 0
Should now not give any linting errors and in this query:
select * from (select 1 as y) t, table(flatten(x))
You would be able to automatically expand column list to replace * with y.
Enable select aliases in where clause
Now this query will not have any lint errors:
select 1 as aliased from (select 1 x) t where aliased
Better support for {{ if }} syntax
Expressions like {{ expr if not loop.last }} gave our parser a bit of trouble. Now this query will not give any lints:
select {% for x in y %} {{ x }} {{ ',' if not loop.last }} {% endfor %} from tbl
Floating point number support for Jinja
Now our parser fully supports floating point numbers in a number of various formats, like .32, 1234.1E37, 1E-37 and others.
Support {% snapshot ... %} blocks
Now our linting and suggestions work with snapshot blocks.
Various bugfixes and small tweaks
- Connection information was sometimes not updated when user enabled and disabled different schemas and databases, causing us to display linting errors. The connection sync mechanism was patched to prevent this from happening.
- Closing a non-focused tab with a mouse could close active tab instead — this no longer happens.
- Connection pane button sometimes get a little dot to indicate that the sync has been complete — but it used to be hard to see visually. We've moved the dot to the side so it would be easier to notice.
- Result table column headers could sometime blend together. We've fixed a transparency issue that caused this.
- Snowflake keypair authentication set up to an invalid path could crash the app. We fixed this and updated error messages to be more helpful.
- Various internal problems that would very rarely occur, but lead to a crash.
- Changed internal project structure to improve interaction and workflow between core of the IDE and our parsing engine.
- Fixed a small issue with parsing
keepalives_idleoption in dbt profiles. - Fixed a rare crash happening when user closes dbt project.
- Fixed small typos in different places of the app.
- Fixed a race condition in our handling of temporary files.
- Happy 2022! We finally updated our copyright year to 2022, and took care that it won't take us 6 months next time.